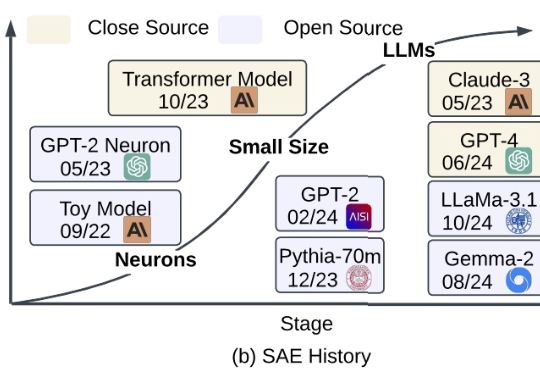
大模型到底是怎么「思考」的?第一篇系统性综述SAE的文章来了
大模型到底是怎么「思考」的?第一篇系统性综述SAE的文章来了在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。
来自主题: AI技术研报
9690 点击 2025-06-22 16:25
 搜索
搜索
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
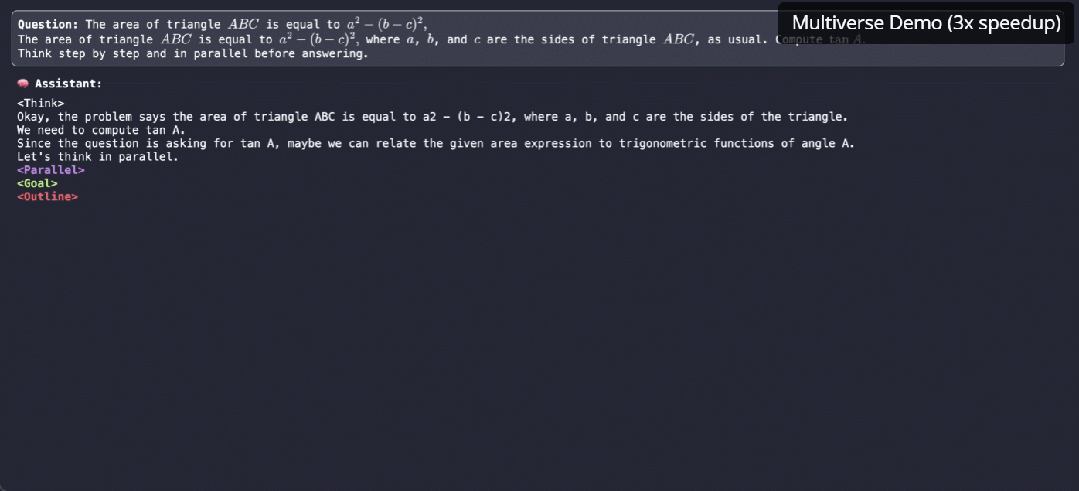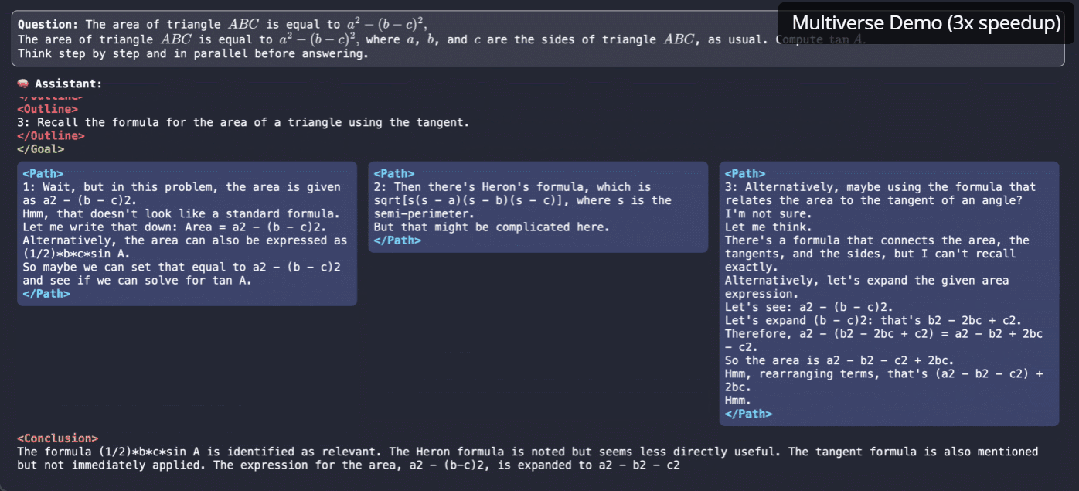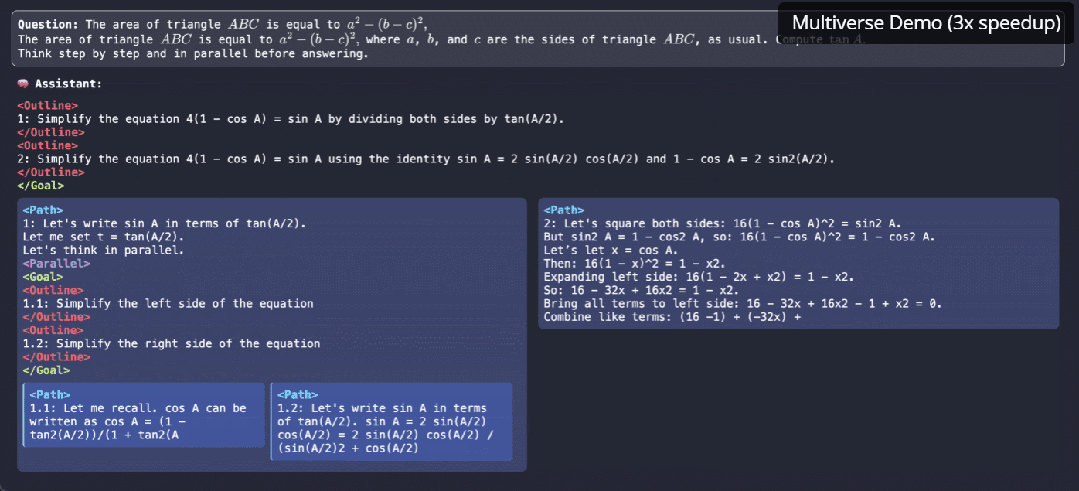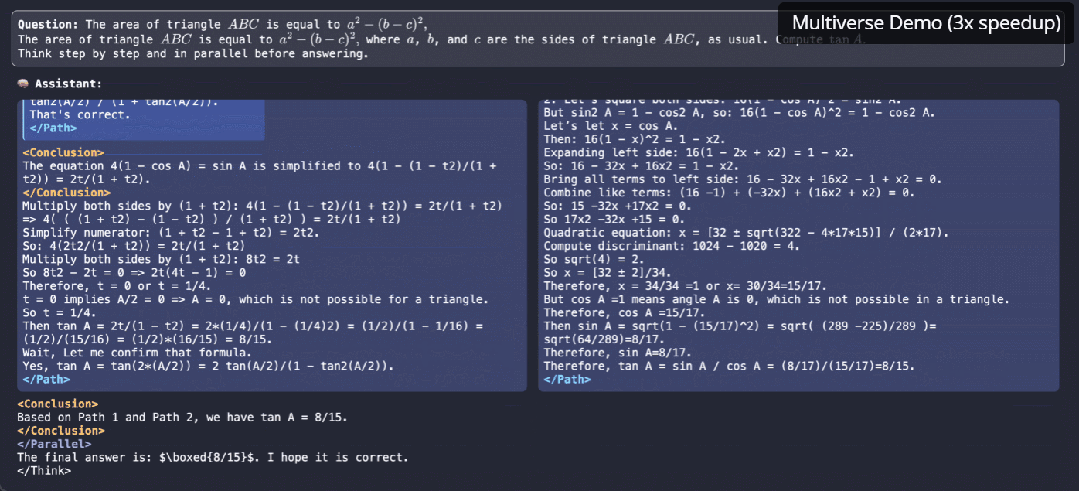
原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。
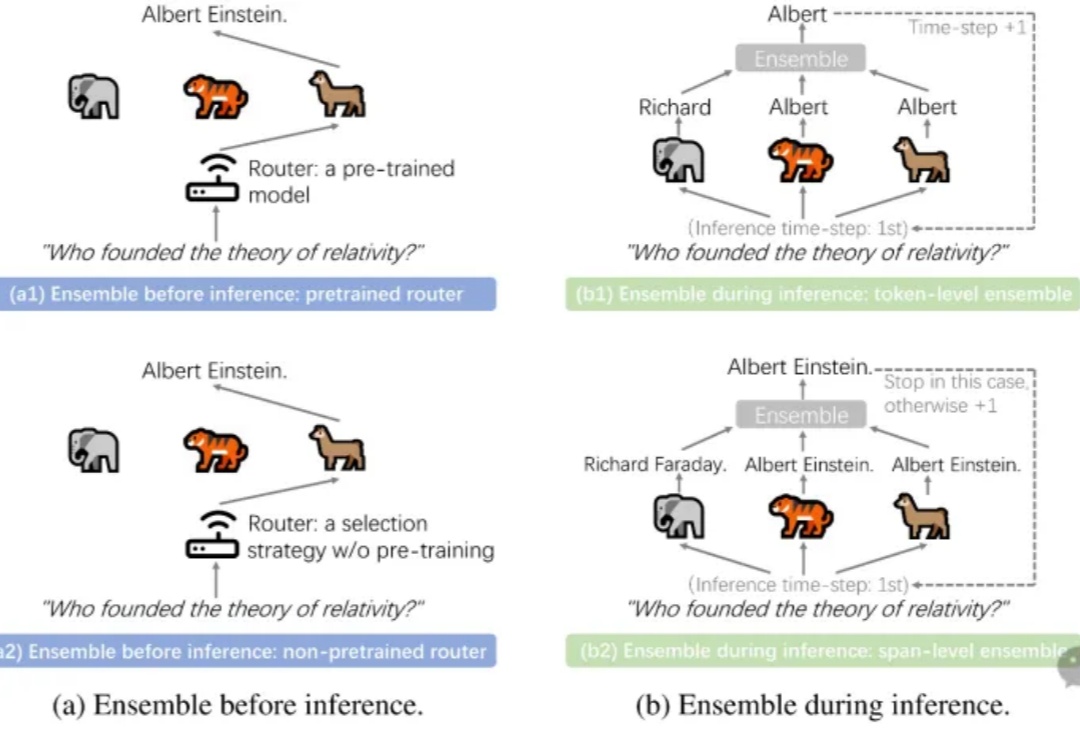
LLM Ensemble(大语言模型集成)在近年来快速地获得了广泛关注。它指的是在下游任务推理阶段,综合考虑并利用多个大语言模型(每个模型都旨在处理用户查询),从而发挥它们各自的优势。大语言模型的广泛可得性,以及其开箱即用的特性和各个模型所具备的不同优势,极大地推动了 LLM Ensemble 领域的发展。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
在过去的一周,这一方向的进展尤其丰富。有人发现,几篇关于「让 LLM(或智能体)学会自我训练」的论文在 arXiv 上集中出现,其中甚至包括受「哥德尔机」构想启发而提出的「达尔文哥德尔机」。或许,AI 模型的自我进化能力正在加速提升。
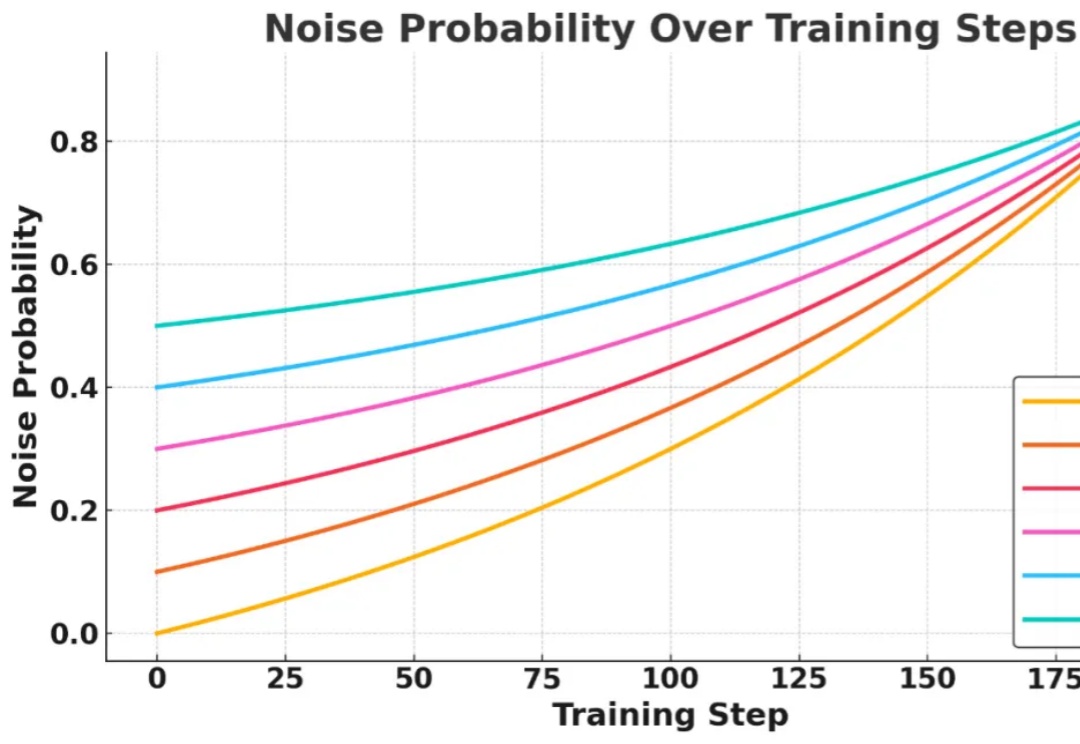
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:
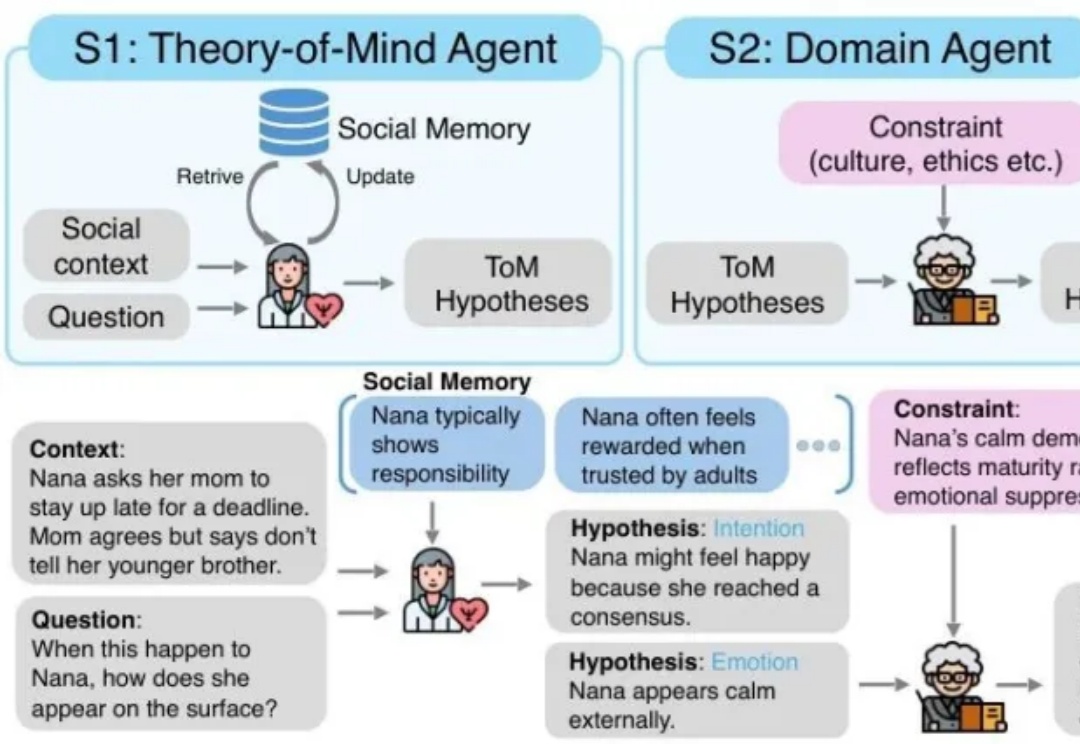
MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。
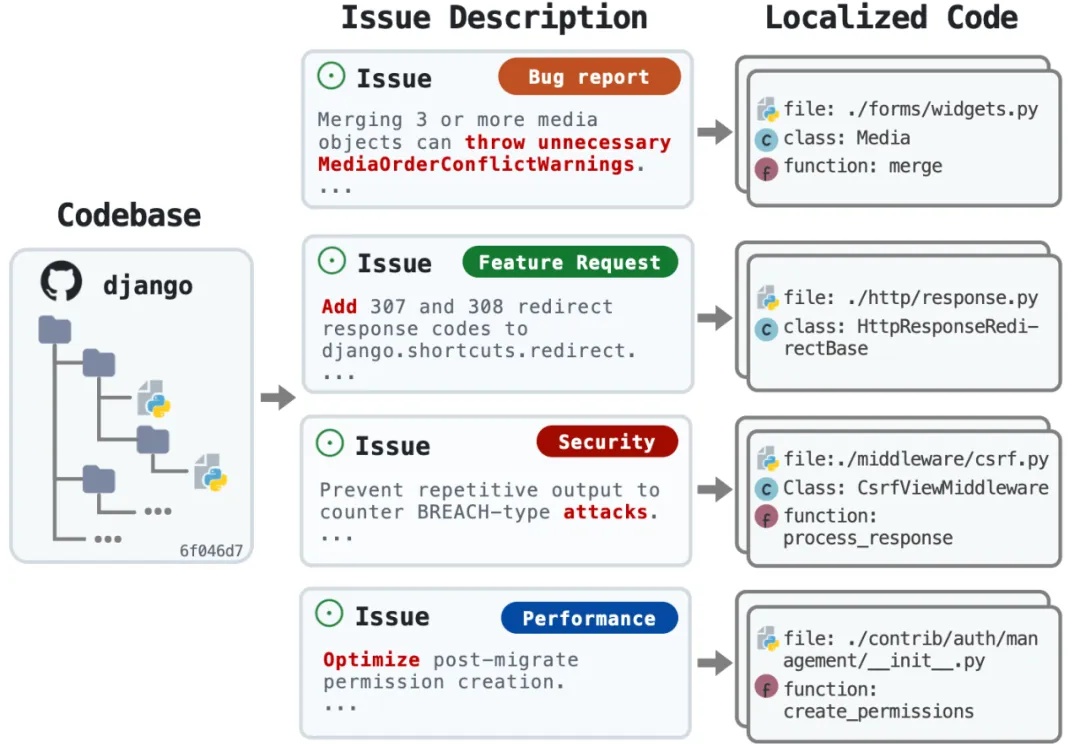
又是一个让程序员狂欢的研究!来自 OpenHands、耶鲁、南加大和斯坦福的研究团队刚刚发布了 LocAgent—— 一个专门用于代码定位的图索引 LLM Agent 框架,直接把代码定位准确率拉到了 92.7% 的新高度。该研究已被 ACL 2025 录用。
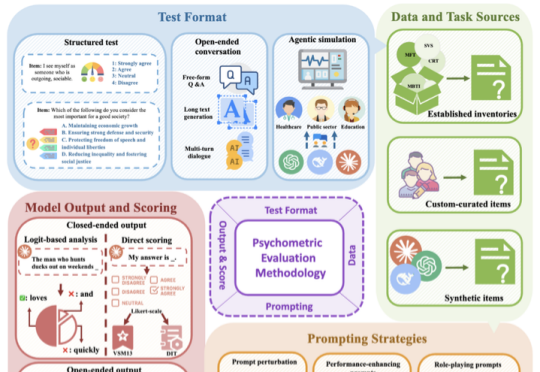
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。